《自然语言处理原理与应用(Principle and Application of Natural Language Processing)》教学大纲
制定时间:2025 年 7 月
一、课程基本信息
(一)适用专业:智能科学与技术
(二)课程代码:
(三)学分/课内学时:3学分/48学时
(四)课程类别:专业教育
(五)课程性质:选修/理论课
(六)先修课程:机器学习、深度学习、概率论与数理统计
(七)后续课程: 机器翻译,语音识别技术,推荐系统
二、课程教学目标
本课程将学习人工智能的一大具体应用方向:自然语言处理。课程不仅会讲解自然语言处理的主要任务和如何基于不同研究范式实现相关任务(包括知识库、统计、神经网络等),而且会重点以案例的形式讲解如何基于实际的自然语言处理框架,针对不同的应用场景进行解决应用问题。使学生能快速具备自然语言处理问题求解的基本思想和初步的自然语言处理软件开发能力。
(一)具体目标
目标1:了解自然语言处理的主要任务,包括分词,序列标注,句法分析,文本分类,文本生成,命名实体识别,信息检索,机器翻译等。
目标2:掌握基于规则或机器学习/深度学习的相关技术;并具备合理运用这些技术的科学思维能力。即具备针对不同的自然语言处理应用场景选择对应的技术的能力;具备自然语言处理问题求解的基本思想和初步的自然语言处理软件开发能力。
(二)课程目标与毕业要求的对应关系
毕业要求 |
毕业要求指标点 |
课程目标 |
教学单元 |
评价方式 |
1. 能够应用数学、自然科学和工程科学的基本原理,识别、表达、并通过文献研究分析智能系统中的复杂工程问题,以获得有效结论。 |
观测点2.5:能运用基本原理分析实际工程的影响因素,证实解决方案的合理性。 |
目标1 |
自然语言处理绪论, NLP相关工具及数学基础, 分词, 序列标注, NLP应用任务 |
课内实验 期末考试 |
2. 具有自主学习和终身学习的意识,有不断学习和适应发展的能力。 |
观测点12.1:具有自主学习和终身学习的意识,具备终身学习的知识基础和自主学习的方法; |
目标2 |
序列标注,NLP应用任务,期末考核 |
课内实验 期末考试 |
三、教学内容与方法
(一)教学内容及要求
序 号 |
教学单元 |
教学内容 |
学习产出要求 |
推荐学时 |
推荐教学方式 |
支撑 课程目标 |
备注 |
1 |
理论1: 自然语言处理绪论 |
自然语言处理发展历史; 具体任务; 应用案例 课程目标; |
了解自然语言处理的历史与前景展望,了解相关任务和应用案例; 了解本课程的学习目标 教学单元安排 |
2 |
讲授 案例 |
目标1 |
|
2 |
理论2: 分词 |
知识要点: 词典 匹配法分词 n-gram |
了解基于规则的分词; 了解字典树; 了解基于统计的分词; 了解n元语法; 掌握分词工具jieba; 熟悉分词评价指标 |
2 |
讲授 案例 |
目标1 |
|
3 |
实验1: 分词 |
分词的实现方法 |
实践分词任务:最大匹配分词 |
2 |
实验 |
目标1 |
|
4 |
理论3: 文本表示(上) |
知识要点: 文本表示的定义,文本的稀疏表示 |
掌握词的文本表示方法:onehot tf-idf |
2 |
讲授 案例 |
目标1 |
|
5 |
理论4: 文本表示(下) |
基于深度学习的表示、稠密表示、词向量与句向量、 |
掌握词的文本表示方法:word2vec;从词到文档 |
2 |
讲授 案例 |
目标1 目标2 |
|
6 |
实验2: 文本表示 |
体会不同的文本表示方法 |
实现从文本到文本表示;实践应用计算词的相似度 |
2 |
实验 |
目标1 目标2 |
|
7 |
理论5: 文本分类(上) |
文本分类的场景,生成式与判别式模型的区别,逻辑回归与朴素贝叶斯 |
了解文本分类任务;掌握分类模型:逻辑回归 朴素贝叶斯 |
2 |
讲授 案例 |
目标1 |
|
8 |
理论6: 文本分类(下) |
基于卡方的特征选择。 学习各种分类评价指标 |
掌握特征工程与特征选择;文本分类的评价指标 |
2 |
讲授 案例 |
目标1 目标2 |
|
9 |
实验3: 文本分类 |
实践朴素贝叶斯和逻辑回归 |
实践文本分类:基于多种模型并灵活运用特征工程实现文本分类 |
2 |
实验 |
目标1 目标2 |
|
10 |
理论7: 文本聚类(上) |
文本聚类的定义,硬聚类与软聚类,Kmeans算法 |
了解文本聚类任务;理解硬聚类与软聚类的定义;掌握kmeans算法 |
2 |
讲授 案例 |
目标1 |
|
11 |
理论8: 文本聚类(下) |
软聚类:基于无监督的聚类方法。EM算法,GMM |
基于无监督学习的聚类;GMM算法;掌握聚类的评测 |
2 |
讲授 案例 |
目标1 目标2 |
|
12 |
实验4: 文本聚类 |
实践文本的硬聚类与软聚类 |
实践文本聚类:基于多种模型并灵活运用特征工程实现文本分类 |
2 |
实验 |
目标1 目标2 |
|
13 |
理论9: 语言模型(上) |
语言模型的定义; 基于统计方法的模型:N-gram; 基于深度学习的模型:RNN系列 |
掌握语言模型 ngram,RNN,LSTM |
2 |
讲授 案例 |
目标1 目标2 |
|
14 |
理论10: 语言模型(下) |
注意力机制的原理;Transformer架构 |
掌握注意力机制,transformer |
2 |
讲授 案例 |
目标1 目标2 |
|
15 |
实验5: 语言模型 |
训练多种语言模型 |
基于自然语言处理任务训练语言模型 |
2 |
实验 |
目标1 目标2 |
|
16 |
理论11: 序列到序列 |
学习编码器解码器架构,进一步了解seq2seq任务 |
掌握编码解码,了解seq2seq |
2 |
讲授 案例 |
目标1 目标2 |
|
17 |
实验6: 序列到序列 |
搭建编码解码架构并应用于NLP任务 |
实践基于编码器解码器的自然语言处理任务 |
2 |
实验 |
目标1 目标2 |
|
18 |
理论12: 预训练模型(上) |
预训练模型的定义和场景;接触经典预训练模型 |
了解预训练模型elmo BERT GPT BART T5 |
2 |
讲授 案例 |
目标1 目标2 |
|
19 |
理论13: 预训练模型(下) |
认识LLM,了解LLM相关的技术和应用 |
了解大语言模型的基本技术与典型应用 |
2 |
讲授 案例 |
目标1 目标2 |
|
20 |
实验7: 预训练模型 |
利用经典的预训练模型完成NLP任务 |
实践基于预训练模型的自然语言处理任务 |
2 |
实验 |
目标1 目标2 |
|
21 |
理论14: 序列标注(上) |
序列标注的定义和场景;HMM模型的原理和应用 |
了解序列标注任务;掌握HMM 模型 |
2 |
讲授 案例 |
目标1 目标2 |
|
22 |
理论15: 序列标注(下) |
CRF模型的原理,神经网络的序列标注任务 |
了解CRF模型;掌握基于神经网络的序列标注 |
2 |
讲授 案例 |
目标1 目标2 |
|
23 |
实验8: 序列标注 |
基于HMM和LSTM-CRF完成序列标注 |
实践基于序列标注的自然语言处理任务 |
2 |
实验 |
目标1 目标2 |
|
24 |
理论16: 期末复习 |
期末复习 |
能回忆本学期的NLP技术和任务;明确期末任务的解决方案 |
2 |
讲授 案例 |
目标1 目标2 |
|
(二)教学方法
本课程注重理论教学与实验的结合,注重学生实践能力的培养,加强实验上机来巩固学生对自然语言处理相关技术的理解,通过实验锻炼学生动手解决自然语言处理相关问题的能力,实验还将以目前比较常见的应用案例为实例,使学生体会自然语言处理的具体作用,通过本课程的学习,学生将全面了解实现自然语言处理的技术,能够在实际项目的研究中运用这些技术加速工作,跟踪前沿的自然语言处理应用场景等,能够为学生从事自然语言处理乃至人工智能相关实践项目打下坚实的基础。
1.课堂讲授
(1)采用启发式教学,激发学生主动学习的兴趣,培养学生独立思考、分析问题和解决问题的能力,引导学生主动通过实践和自学获得自己想学到的知识。
(2)在教学内容上,系统讲授自然语言处理的基本理论、基本知识和基本方法,使学生能够系统掌握用于解决智能科学类专业工程复杂问题的专业基础知识。
(3)在教学过程中采用电子教案,Jupyter Notebook课件,多媒体教学与传统板书、教具教学相结合,提高课堂教学信息量,增强教学的直观性。
(4)理论教学与工程实践相结合,引导学生应用数学、自然科学和工程科学的基本原理,采用现代设计方法和手段,进行问题分析、综合与仿真,培养其识别、表达和解决智能类专业相关工程问题的思维方法和实践能力。
(5)课内讨论和课外答疑相结合,每周至少一次进行答疑。
2. 实验教学
实验教学是本课程中重要的实践环节,目的是培养学生运用实验方法研究解决智能类专业复杂工程问题的能力。课程必做实验8个,各实验要求学生独立或分组完成,并提交实验报告至少4次。
3. 专题研究
围绕本课程教学重点内容,设置专题研究环节,培养学生逐步具有应用机器学习,深度学习等技术解决自然语言处理的应用问题的能力,结合所研究课题进行报告和设计报告的撰写,并清晰陈述观点和回答问题的能力。
组织形式及要求如下:
(1)学生从教师给定的题目中选择或自主选题,以小组为单位进行,每个人的分工与责任需明确,并在报告中提供小组研讨情况记录及说明;
(2)选题应结合具体任务的需求,设计自然语言处理应用程序,给出设计成果,撰写研究报告,并进行陈述与答辩。
四、考核及成绩评定
(一)考核内容及成绩构成
课程目标 |
考核内容 |
成绩评定方式 |
成绩占总评分比例 |
目标成绩占当次考核比例 |
学生当次考核平均得分 |
目标达成情况计算公式 |
目标1:了解自然语言处理的主要任务,包括分词,序列标注,句法分析,文本分类,文本生成,命名实体识别,信息检索,机器翻译等。 |
分词,序列标注等任务 |
实验 |
20% |
100% |
A1 |
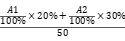
|
阐述自然语言处理任务的实现原理 |
期末 |
30% |
100% |
A2 |
目标2:掌握基于规则或机器学习/深度学习的相关技术;并具备合理运用这些技术的科学思维能力。即具备针对不同的自然语言处理应用场景选择对应的技术的能力;具备自然语言处理问题求解的基本思想和初步的自然语言处理软件开发能力。 |
分析自然语言处理实现的规则和机器学习技术并提交实验报告 |
实验 |
20% |
100% |
B1 |
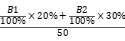
|
灵活使用掌握的自然语言处理技术,从头到尾实现一个自然语言处理的综合任务并提交报告 |
期末 |
30% |
100% |
B2 |
总评成绩(100%)= 实验(40%)+期末(60%) |
100% |
—— |
—— |

|
(二)实验考核成绩评定
1.支撑目标1、目标2,共占总评分40%,目标1占20%、目标2占20%。对应目标的评分标准如下:
对应目标 |
目标1:了解自然语言处理的主要任务,包括分词,序列标注,句法分析,文本分类,文本生成,命名实体识别,信息检索,机器翻译等。 |
目标2:掌握基于规则或机器学习/深度学习的相关技术; 具备针对不同的自然语言处理应用场景选择对应的技术的能力;具备自然语言处理问题求解的基本思想和初步的自然语言处理软件开发能力。 |
考查点 |
实验内容 |
实验报告 |
占总成绩比例 |
20% |
20% |
评分标准 |
100% 至 90% |
实验记录全部完成无遗漏,内容丰富、图文并茂,流程图数量足够且正确,实验方案有自己独到的思路与见解。 实验记录全部完成无遗漏,内容丰富、图文并茂,流程图数量足够且正确,实验方案有自己独到的思路与见解。 |
有很强的总结实验和撰写报告的能力,实验报告内容完整、正确,有很好的分析与见解。文本表述清晰,书写工整,格式规范。 |
89.9% 至 80% |
实验记录比较完整,内容比较丰富、图文并茂,流程图数量足够且基本正确,实验方案有自己的思路与见解。 |
有较强的总结实验和撰写报告的能力,实验报告内容完整、正确,有较好的分析与见解。文本表述较为清晰,书写比较工整,格式规范。 |
79.9 至 70% |
实验记录比较完整,内容比较丰富,流程图数量足够且基本正确。 |
有良好的总结实验和撰写报告的能力,实验报告内容较完整、正确,有自己的分析与见解。文本表述较为清晰,书写较为工整,格式较为规范。 |
69.9% 至 60% |
实验记录基本完整,内容基本够,流程图数量基本够但有少量错误。 |
有一定的总结实验和撰写报告的能力,实验报告内容基本完整、正确,没有分析或见解。文本表述基本清晰,书写基本工整,格式基本规范。 |
59.9%至 0 |
实验记录未完成,内容不够,流程图数量不够、错误多。 |
总结实验和撰写报告的能力差,实验报告内容不完整、错误多。文本表述不清晰,书写潦草、格式不规范。 |
五、参考学习资料
(一)推荐教材:
1. 屠可伟等, 动手学自然语言处理,人民邮电出版社,2024
2.何晗 著 自然语言处理入门 ISBN:9787115519764 人民邮电出版社,2019
3. 斋藤康毅(日) 著 陆宇杰 译. 深度学习进阶-自然语言处理,ISBN:9787115547644. 北京:人民邮电出版社,2020.
(二)在线资源:
1. 《自然语言处理入门》 配套资源
https://od.hankcs.com/
2 《深度学习进阶 自然语言处理》 配套资源 官方发布
https://github.com/oreilly-japan/deep-learning-from-scratch-2
 学校地址:重庆沙坪坝区大学城东路20号
学校地址:重庆沙坪坝区大学城东路20号  邮编:401331
邮编:401331 学院教学服务:65023467 学院学生管理:65023123
学院教学服务:65023467 学院学生管理:65023123


