《大数据共享与整合技术( Big data Sharing and Integration Technology)》教学大纲
制定时间:2025年04月
一、课程基本信息
(一)适用专业:本科物联网工程
(二)课程代码:3DX1056A
(三)学分/课内学时:2学分/32学时
(四)课程类别:专业教育
(五)课程性质:选修/理论课
(六)先修课程:Python语言基础、数据库应用、 计算机网络
(七)后续课程:大数据共享与整合技术实践、大数据智能分析与决策,毕业设计
二、课程教学目标
本课程是一门新兴的交叉性学科,涵盖了数据库、机器学习、统计学、模式识别、人工智能以及高性能计算等技术。开设本课程的目的,是使学生全面而深入地掌握大数据处理的基本概念和原理,掌握常用的大数据处理算法,了解大数据处理的最新发展、前沿的大数据处理研究领域、以及大数据处理技术在不同学科中的应用。为学生学习后续物联网新技术、毕业设计打下基础。
本课程的主要任务是通过课堂教学、示范演示教学等环节培养学生的创新意识与能力和计算机学科知识的应用能力,使学生掌握自动识别技术和大数据处理的基本理论、基本知识和基本技能,常用基本算法的分析和数据分析的一般规律,具有基本的大数据处理能力,以及对自动识别技术问题进行分析、求解和论证的能力,支撑毕业要求中的相应指标点。使学生既能清楚地理解自动识别技术的工作原理,又能掌握现代主流的自动识别技术,构建和培养出学生完整的系统观念和严谨细致的工作作风。
(一)具体目标
目标1:具备较强的学习最新大数据处理领域研究成果的能力。了解由工程问题,到建模、再到大数据处理算法设计的问题求解思维模式。
目标2:能够设计并实现大数据平台下的大数据处理系统,掌握大数据预处理、关联规则、大数据基本处理能力,并能够在主流大数据平台上实现,具有将大数据处理算法应用于具体工程的能力。
(二)课程目标与毕业要求的对应关系
毕业要求 |
毕业要求指标点 |
课程目标 |
教学单元 |
评价方式 |
1. 掌握本专业必需的数学、自然科学、工程基础和专业知识,能够用于解决物联网领域中的复杂工程问题。 |
1.6:掌握大数据共享与整合技术、大数据挖掘分析与应用等专业知识,能将其用于物联网工程中的服务器资源整合、大数据存储和分析; |
目标1 |
大数据分析入门 |
非标大作业 |
2. 掌握本专业必需的数学、自然科学、工程基础和专业知识,能够用于解决物联网领域中的复杂工程问题。 |
2:掌握大数据共享与整合技术、大数据挖掘分析与应用等专业知识,能将其用于物联网工程中的服务器资源整合、大数据存储和分析; 能正确采集和整理数据,对结果进行分析和解释,获取有效结论; 能选用合适的云平台 和人工智能方法,应用大数据工具实现大数据分析。 |
目标2 |
大数据预处理、机器学习算法-线性回归、一元线性回归算法Python |
实验 非标大作业 |
3. 能够针对大数据领域的复杂工程问题,分析、选择与使用恰当的技术、资源、现代工程工具和信息技术工具,实现对复杂工程问题的预测与模拟,并能够理解其局限性。 |
3:能够实现现实环境中的大数据分析整合项目。 |
目标2 |
分类算法介绍、KNN分类算法介绍、KNN分类算法实现、聚类算法概论、k-means算法Python实现。 |
实验 非标大作业 |
三、教学内容与方法
(一)教学内容及要求
序 号 |
教学单元 |
教学内容 (知识点) |
学习产出要求 |
推荐学时 |
推荐教学方式 |
支撑 教学目标 |
备注 |
1 |
大数据处理概论 |
了解大数据处理和智能决策概念及其发展过程,在各行业中的典型应用,以及大数据处理的过程。 |
理解大数据处理的概念,掌握各类识别方法。了解各种大数据处理技术和发展趋势。 |
2 |
讲授 |
目标1 |
|
2 |
基础数学知识 |
向量、矩阵、协方差等在大数据处理中经常涉及到的数学工具和概念 |
了解向量、矩阵、协方差等概念在大数据处理过程中的应用和评价 |
2 |
讲授 |
目标1 |
|
3 |
大数据预处理 |
数据预处理的概念,为什么要进行数据预处理,评价数据质量的指标,数据清洗和数据填充的方法,数据平滑的方法。 |
了解数据预处理的概念,数据预处理的方法;掌握数据填充和数据平滑的方法。 |
2 |
讲授 |
目标1 |
|
4 |
机器学习算法-线性回归 |
本章首先简单介绍机器学习中回归的基本概念,接着介绍回归算法中最简单的一元线性回归的概念,理解线性回归中误差函数使用平方和的原因,能使用梯度下降法求解误差函数。 |
理解回归分析的基本思想;会求经验回归系数,掌握一元线性回归方程的求法,会将一元非线性模型转化为一元线性模型。 |
4 |
讲授 |
目标2 |
|
5 |
聚类算法概论 |
掌握相似性和相异性度量,了解聚类算法的分类。 |
掌握聚类中相异性度量的概念、掌握核心的聚类算法,了解不同算法的优缺点。 |
2 |
讲授 |
目标2 |
|
6 |
聚类算法基础理论 |
掌握无监督学习的概念,讲述邻居的概念,掌握欧式距离、数据特征和样本间的相似度的概念。 |
了解聚类算法的基础概念。 |
2 |
讲授 |
目标2 |
|
7 |
聚类算法典型算法 |
掌握K-means算法的思想与流程,掌握K-means算法的伪代码。了解信息熵的概念,以及基于熵的聚类算法。 |
了解K-means算法的原理,对其数学机理熟练掌握。 |
2 |
讲授 |
目标2 |
|
8 |
分类算法介绍 |
分类算法简介、分类的基本流程、常用的分类算法介绍。 |
了解分类的概念、特点、常用的分类算法、熟悉分类的基本流程。 |
2 |
讲授 |
目标2 |
|
9 |
KNN分类算法介绍 |
KNN算法概述、KNN算法的实现步骤。 |
了解KNN分类的概念、特点。熟悉KNN算法的实现步骤。 |
2 |
|
目标2 |
|
10 |
距离度量 |
大数据中的距离度量方法 |
了解各种距离度量解决方法:欧几里得距离,标准化欧氏距离,明可夫斯基距离,曼哈顿距离,切比雪夫距离,马哈拉诺比斯距离 |
2 |
|
目标2 |
|
11 |
实验1:大数据分析编程环境配置和简单大数据处理 |
了解大数据分析工具软件的功能特色和工作环境,掌握应用Python进行大数据分析的能力。了解开发大数据项目的解决方案的基本概念。 |
下载并安装Python、pycharm工具;熟悉Python编程;实现简单大数据处理 |
4 |
|
目标1 |
|
12 |
实验2:一元线性回归算法的实现 |
利用Python设计一个简单的一元线性回归算法的实现。 |
设计一个简单的一元线性回归算法的实现。 |
2 |
讲授 示范 实操 |
目标2 |
|
13 |
实验3:k-means算法Python实现 |
利用Python自带工具箱的k-means算法,设计一个简单的聚类算法,能够显示聚类过程以及聚类结果。 |
了解Python软件k-means工具箱的使用方法,设计一个简单的聚类算法,能够显示聚类过程以及聚类结果。 |
2 |
讲授 示范 实操 |
目标2 |
|
14 |
实验4:KNN算法的Python实现 |
KNN算法实现的详细步骤、KNN算法的数学模型、通过PYTHON编程实现KNN分类算法的基本实现案例、KNN算法关键参数的详解。 |
实现KNN分类算法的基本实现案例、KNN算法关键参数的详解 |
2 |
讲授 示范 实操 |
目标2 |
|
(二)教学方法
1.课堂讲授
(1)采用启发式教学,激发学生主动学习的兴趣,培养学生独立思考、分析问题和解决问题的能力,引导学生主动通过自学和工程实践提升对于理论知识的理解。
(2)在教学内容上,系统讲授软件需求工程的基本理论和技术,指导学生完成对需求调研与获取、需求分析、概要设计和详细设计等内容的学习,使学生能够系统掌握软件需求分析的专业知识。
(3)在教学过程中采用电子教案,多媒体教学与传统板书、教具教学相结合,提高课堂教学信息量,增强教学的直观性。
(4)理论教学与工程实践相结合,采用案例式教学,将学生经常使用的软件设计成具体的工程案例用于课堂练习,引导学生掌握软件需求工程的思维方法和实践能力。
2.实验教学
实验教学是软件需求分析课程中重要的实践环节,目的是培养学生运用实验方法掌握软件需求分析的实践技能。通过侧重点不同的设计性实验以及最后的综合性实验,使得学生逐步构建起软件需求分析的完整工程实践能力。课程必做实验5个,各实验按照实验指导书的要求学生独立或分组完成,并提交实验报告。
鼓励学生选择自己熟悉的软件产品作为综合性实验的需求分析对象。
四、考核及成绩评定
(一)考核内容及成绩构成
课程考核以考核学生能力培养目标的达成为主要目的,以检查学生对各知识点的掌握程度和应用能力为重要内容,包括实验和试卷考核两个部分,考核方式:考查。各课程目标的考核内容、成绩评定方式、目标分值建议如下:
课程目标 |
考核内容 |
成绩评定方式 |
成绩占总评分比例 |
目标成绩占当次考核比例 |
学生当次考核平均得分 |
目标达成情况计算公式 |
目标1:具备较强的学习最新大数据处理领域研究成果的能力。了解由工程问题,到建模、再到大数据处理算法设计的问题求解思维模式。 |
熟悉大数据平台下的大数据处理系统。由工程问题,到建模、再到大数据处理算法设计的问题求解思维模式。 |
非标大作业 |
15% |
25% |
A1 |
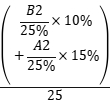
|
熟悉Python安装、配置和使用,能实现简单的大数据处理。 |
实验 |
10% |
25% |
B2 |
目标2:能够设计并实现大数据平台下的大数据处理系统,掌握大数据预处理、关联规则、大数据基本处理能力,并能够在主流大数据平台上实现,具有将大数据处理算法应用于具体工程的能力。 |
掌握K-means和KNN高级大数据处理能力。 |
实验 |
30% |
75% |
B2 |
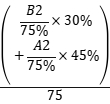
|
掌握大数据简单处理能力,熟悉回归分析。掌握高级大数据处理能力 |
非标大作业 |
45% |
75% |
A2 |
总评成绩(100%)=平时实验(40%)+非标大作业(60%) |
100% |
—— |
—— |

|
(二)平时考核成绩评定
1.实验:平时必做实验4次。支撑目标1和2,共占总评分40%。对应目标的评分标准如下:
对应目标 |
目标1:具备较强的学习最新大数据处理领域研究成果的能力。了解由工程问题,到建模、再到大数据处理算法设计的问题求解思维模式。 |
目标2:掌握大数据预处理方法,掌握Python的基本处理技术。 |
目标2:通过对本门课程的学习,学生能够有效地解决一些实际的大数据分析任务。 |
考查点 |
实验过程 |
实验报告 |
实验报告 |
成绩比例 |
10% |
20% |
10% |
评分标准 |
100% 至 90% |
能够完全理解大数据的概念和各阶段任务;熟练掌握大数据的理论并能运用到实验中。完全掌握数据处理等方面的知识和技巧;能够准确地分析复杂数据得到分析结论。 |
综合性实验的报告能够完全体现对于大数据预处理的专业性和准确性,报告前后描述逻辑合理;所有数据得到准确的处理。 |
能够熟练运用大数据处理方法处理大数据;理解大数据处理方法的理论;能够有效地运用Python语言实战处理大数据;能够根据实验任务书的要求,完成大数据预处理和分析,并撰写报告。 |
89.9% 至 80% |
能够较好地理解大数据的概念和各阶段任务;掌握大数据的理论并能运用到实验中。较好地掌握数据处理等方面的知识和技巧;能够较准确地分析复杂数据得到分析结论。 |
综合性实验的报告能够完全体现对于大数据预处理的专业性和准确性,前后描述逻辑基本合理;所有数据得到较好的处理。 |
能够较好地运用大数据处理方法处理大数据;掌握大数据处理方法的理论;能够较好地运用Python语言实战处理大数据;能够根据实验任务书的要求,完成大数据预处理和分析,并撰写报告。 |
79.9 至 70% |
基本理解大数据的概念和各阶段任务;掌握大数据的理论并能运用到实验中。基本掌握数据处理等方面的知识和技巧;基本能够分析复杂数据得到分析结论。 |
综合性实验的报告能够完全体现对于大数据预处理的专业性和准确性,前后描述逻辑基本合理;所有数据得到基本的处理。 |
能够基本运用大数据处理方法处理大数据;掌握大数据处理方法的理论;能够基本运用Python语言实战处理大数据;能够根据实验任务书的要求,完成大数据预处理和分析,并撰写报告。 |
69.9% 至 60% |
基本理解大数据的概念和各阶段任务;掌握大数据的理论但不能较好地运用到实验中。基本掌握数据处理等方面的知识和技巧;能够分析简单数据得到分析结论。 |
综合性实验的报告能够完全体现对于大数据预处理的专业性和准确性,前后描述逻辑基本合理;所有数据无法得到较好的处理。 |
能够基本运用大数据处理方法处理大数据;掌握大数据处理方法的理论;能够基本运用Python语言实战处理大数据;不能完全根据实验任务书的要求,完成大数据基本处理和分析。 |
59.9%至 0 |
不能理解大数据的概念和各阶段任务;掌握大数据的理论但不能运用到实验中。不能掌握数据处理等方面的知识和技巧;不能分析简单数据得到分析结论。 |
综合性实验的报告能够完全体现对于大数据预处理的专业性和准确性,前后描述逻辑不合理;所有数据无法得到处理。 |
不能运用大数据处理方法处理大数据;不能完全掌握大数据处理方法的理论;不能运用Python语言实战处理大数据;不能根据实验任务书的要求,完成大数据预处理和分析。 |
五、参考学习资料
(一)推荐教材1:《Python数据挖掘与机器学习》,魏伟一 张国治,清华大学出版社,2021,第1版,ISBN:9787302572992.
(二)推荐教材2:《数据分析(第2版)》,范金城, 梅长林,科学出版社,2010,第2版,ISBN:9787030263728.
 学校地址:重庆沙坪坝区大学城东路20号
学校地址:重庆沙坪坝区大学城东路20号  邮编:401331
邮编:401331 学院教学服务:65023467 学院学生管理:65023123
学院教学服务:65023467 学院学生管理:65023123


